
Содержание
Когда мы хотим провести кластерный анализ для выявления групп в наших данных, мы часто используем алгоритмы типа метода k-средних, которые требуют задания количества кластеров. Но проблема в том, что мы обычно не знаем, сколько кластеров существует. Однако необходимо подчеркнуть, что в данном исследовании цепной кластер менее информативен, чем ассоциативный, тем не менее он предоставляет дополнительные к ассоциативному кластеру сведения.
В данном исследовании на предварительном этапе использованы методы корреляционного анализа, позволившие убрать из рассмотрения факторы с сильной корреляционной зависимостью. В качестве инструментальных средств проведения исследования использованы прикладные пакеты программ в среде Python, а также среда для анализа данных RStudio. Исследование проводилось по четырем группам факторных признаков, отражающих различные стороны развития регионов.
Анализ данных и поиск решений
КСЛСТАТ содержит более 200 основных и расширенных статистических средств, включающих все функции пакета анализа. Существуют несколько сторонних надстроек, которые предоставляют функции пакета анализа для Excel 2011. В экономическом анализе – при изучении и прогнозировании экономической депрессии, исследовании конъюнктуры. Допустим, по регионам Российской Федерации имеется информация об объемах производства четырех видов продукции (пиломатериалы, трикотаж, мясо и хлеб) индивидуальными предпринимателями.
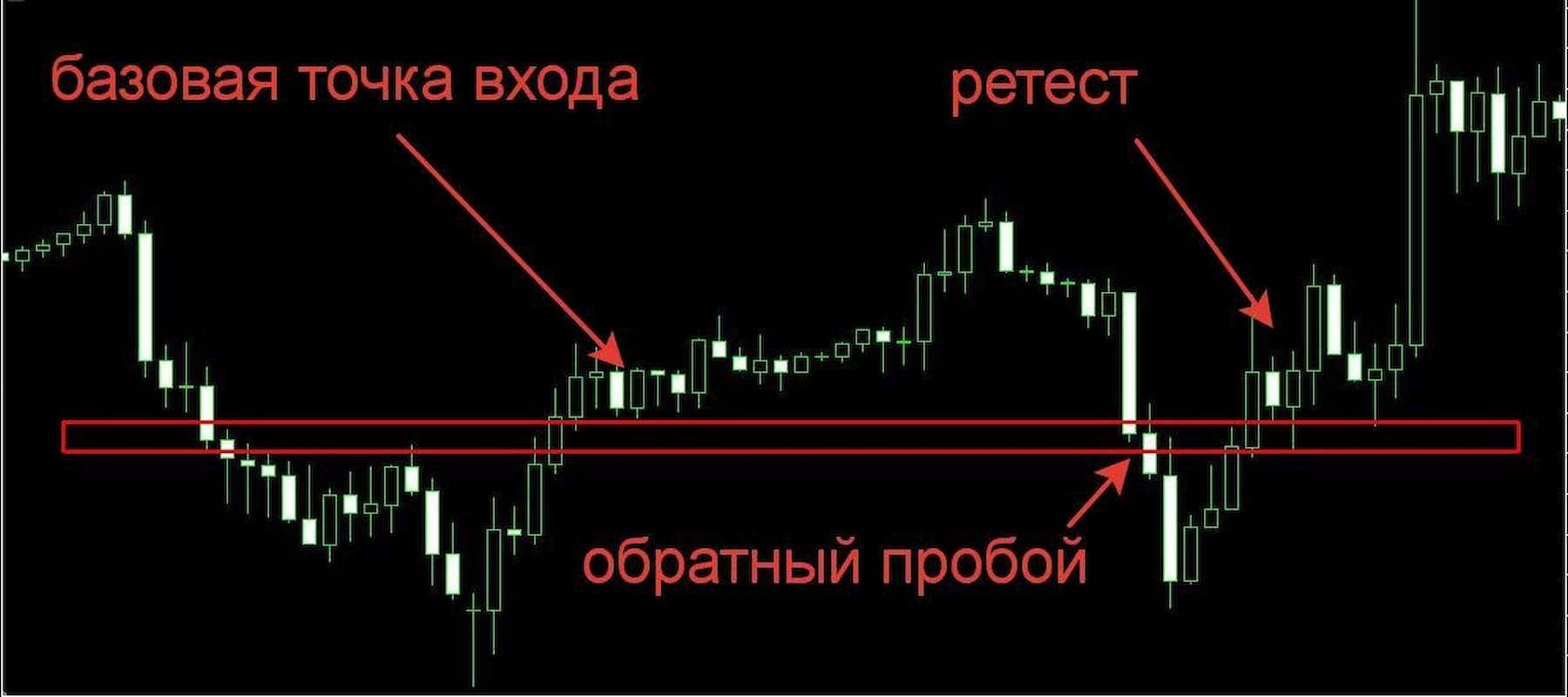
Наблюдая за критическим выбросом во время активного рынка, можно ожидать трендовый разворот. Если при нисходящем движении формируются крупные объёмы на покупку, то с большой вероятностью на графике скоро сформируется экстремум либо смена тенденции. Сравнивая значения объемов друг с другом, мы можем видеть самые большие вливания денег, а большие вливания денег часто приводит либо к остановке, либо полному развороту тренда. Ниже представлены 2 графика движения рынка за один торговый день. Чтобы вы увидели отличие свечного графика от кластерного, давайте рассмотрим конкретный пример.
Анализ приведенных выше корреляционных диаграмм позволяет сделать следующие выводы. По первой группе факторных признаков высокой корреляционной зависимости не наблюдается. По второй группе наблюдается высокая корреляционная зависимость между фактическим потреблением и доходами на душу населения. Кроме того, достаточно высока связь между уровнем безработицы и числом заболевших на населения.
- Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя.
- Если вы устали, напряжены, нервничаете, то вероятность ошибки возрастает.
- На первом этапе матрица смешения (оценки людей по различным характеристикам) преобразуется в матрицу расстояний.
- Используя дельту, можно судить о преобладании на рынке продаж или покупок.
- Желая достигнуть качественного сегментирования, аналитик должен стремиться найти лучший вариант кластеризации, «лучший» в смысле оптимального значения меры сходства.
- Этот параметр доступен только для модели «дерево принятия решений».This option is only available if you build a Decision Tree model.
- Кластер – это группы объектов, выделенные в результате кластерного анализа на основе заданной меры сходства или различий между объектами.
Далее процедура повторяется для второго элемента, причем первый из процесса отбора исключается. Процесс повторяется столько раз, сколько элементов в множестве M. Обычно в методе k-means реализуется процедура построения усредненных профилей каждого класса (см. рис. 3), что дает возможность проводить качественный анализ выраженности признаков у представителей каждого класса. На практике высокий уровень точности, достигаемый при реализации вычислительных алгоритмов кластеризации, очень часто оказывается невостребованным.
В таких ситуациях можно дождаться момента, когда рынок перейдет к тренду и тогда «поймать» хорошее движение. Те, кому это удается, могут рассчитывать на достаточно неплохой профит. Перед тем, как мы перейдем к практической части, немного теории. И, хотя, Форекс является внебиржевым, здесь тоже всегда есть как покупатели, так и продавцы. Изменение котировок одного актива обычно включат цепочку связанных событий по другим финансовым инструментам.
Программы для построения кластерных графиков
В этом случае не возникают какие-либо сложности с применением коэффициентов важности в мерах сходства. Это позволяет учесть роль отдельных переменных для построения оценок сегментов. Наибольшее распространение в процедурах кластерного анализа получили меры сходства, построенные на мерах расстояния и коэффициентах корреляции. Эти два типа меры, как правило, в полном объеме удовлетворяют запросам аналитика по описанию схожести потребителей, которых следует разделить на сегменты. Более тонкие меры сходства вызывают у аналитика сложности в изучении их возможностей применения.
Это могут быть как количественные, так и категориальные переменные в зависимости от метода кластерного анализа. Итак, главная цель кластерного анализа – нахождение групп схожих объектов в выборке. Методы кластерного анализа представляют в большинстве своем эвристические процедуры. Эвристические правила, используемые для решения этой задачи, позволяют снизить затраты времени на поиск однородных групп. При этом очевидно, что получаемые группы не являются оптимальными в точном математическом смысле. Методы, обеспечивающие получение приемлемого решения, называются эвристическими.
Пример использования кластерного анализа STATISTICA в автостраховании
Он позволяет видеть результат тех сделок, которые совершались на конкретном ценовом уровне за определенный период времени. Но ведь любое движение рынка измеряется сделками, а любая сделка дает информацию, о которой многие трейдеры забывают и никогда не принимают в расчет. Это объем, время, в которое данный объем сформировался, и цена, по которой данная сделка прошла. Существует много разных платформ, в которых можно представить график в виде кластеров.
На настоящий момент именно эта информационно-богатая диагностическая база обеспечивает понимание профиля тела с его соматическими и психологическими связями. Объединяем эти данные в группу кластерный анализ трейдинг и формируем новую матрицу, в которой значения 1,2 выступают отдельным элементом. При составлении матрицы оставляем наименьшие значения из предыдущей таблицы для объединенного элемента.
Сходство и различие между потребителями устанавливаются в соответствии с метрическими расстояниями между точками, которые представляют изучаемых потребителей. Итак, мы показали, какая задача может быть решена методами сегментирования, и как для ее решения могут быть подготовлены исходные данные. Дальнейшее объяснение методов сегментирования будем сопровождать иллюстрациями, которые построены на материалах данного примера.
Анализ по методу кластер-профиля
Также клиентами фирмы являются столовые крупных промышленных предприятий и государственных учреждений. Также среди ее клиентов есть и такие, которые расположены в сельской местности, в пригородах и в районных центрах области. Процедура оценки выделяемых кластеров как прототипов сегментов может проводиться в два этапа.

Термин «кластерный анализ» обозначает множество вычислительных процедур, используемых при классификации объектов. В результате применения классифицирующих процедур создаются «кластеры», или группы очень похожих объектов. Здесь мы обращаем внимание читателя на то, что группа схожих объектов именуется «кластером», а не «сегментом». Кластер будем рассматривать как сегмент, если он удовлетворяет требованиям системного подхода, которые мы обсуждали в пункте «Свойства сегментов». Одним из инструментов для решения экономических задач является кластерный анализ. С его помощью кластеры и другие объекты массива данных классифицируются по группам.
Аналитик должен оттолкнуться от факта существования групп потребителей, создавая свои маркетинговые программы по работе с выделяемым сегментом. Следует обратить внимание читателя на следующую особенность алгоритмов кластерного анализа. Выше мы рассмотрели автоматическую процедуру расчета центров кластеров на основе построения случайных выборок из анализируемой совокупности объектов. Плотность можно определить как число точек объектов, приходящихся на единицу пространства, ограниченного переменными сегментирования. Этот параметр позволяет определить кластер как скопление точек в пространстве данных, относительно плотное по сравнению с другими областями пространства. Целесообразность нормирования значений переменных можно показать на следующем примере.
Как используется кластерный анализ в трейдинге?
Общая методология сводится к введению априорной плотности распределения параметров и последующему нахождению по формуле Байеса их апостериорной плотности распределения (с учетом экспериментальных данных). Характеристический параметр класса r – матрица вероятности появления определенного ответа на i-й вопрос, если испытуемый относится к k-му классу. Мы задавали его и одинаковым для испытуемых, принадлежащих к одному классу, и различным для каждого класса. Предполагается, что условная вероятность такого события, как ответ испытуемого категории q на j вопрос, постоянна для всех испытуемых, принадлежащих к классу k.
Мы видим лишь конечные точки (по окончании временного периода). Профиль кластера — отражает общие объемы в свече без разделения покупок или продаж, т.е. Мы видим активность, но не понимаем, кто в итоге инициатор.
Совокупный результат торгов определяется числом внутри кластера. Первая часть данных используется для обучения, https://boriscooper.org/ а вторая – для применения того, что изучено. И всё это менее чем за секунду даже при большом объеме данных.
Кластерный анализ
Целью данного анализа является разбиение автомобилей и их владельцев на классы, каждый из которых соответствует определенной рисковой группе. Наблюдения, попавшие в одну группу, характеризуются одинаковой вероятностью наступления страхового случая, которая впоследствии оценивается страховщиком. Глядя на ситуацию, мы видим, что перекрытие между видами гораздо выше, чем раньше. Кроме того, мы знаем, что существует три кластера, но это не означает, что данные способны их различать. В этом случае может быть особенно сложно отличить пингвинов Адели от антарктических пингвинов.
Если эта статья была полезной, то планирую опубликовать продолжение. В исходной выборке там меньше всего индивидов, и они очень близки по предпочтениям в алкоголе, согласно данным, к центральной части. Можно попробовать условно разделить на два кластера, так как видно, что для интерпретации лучше всего так и сделать и резюмировать биполярность Европы. Тогда кластера практически совпадут с Восточной и Западной Европой, где в Западную войдет центральная и Западная по исходным обозначениям. Если бы она была покучнее, можно было говорить о кластеризации, а так это, скорее, сегментация. В целом, между группами заметно различие, посмотрим, как справится метод k-средних++.
Определение и логика кластерного анализа в трейдинге
По этим графикам можно предположить наличие 3–4 кластеров по аналогии с кластерограммой, но они не очень убедительны. Мы также можем проверить некоторую дополнительную информацию, например оценку силуэта или оценку Калинского — Харабазса. Вероятность появления ответа категории q(1,2,…,Q) равна вероятности q, являющейся суммой реализаций дихотомической случайной переменной. Применение дендритного анализа к рассматриваемым данным позволило получить следующий дендрит (см. рис. 2). Первые две стратегии изменяют пространство (сужают и растягивают), а последняя его не изменяет. Где ni , nj , nk– число объектов соответственно в классах i, j,k.